|
Major Member
 加入日期: Dec 2002
文章: 156
|
引用:
這四個指令都是屬於 arithmetic 但一個程式碼屬於 scalar operation 第二個程式碼屬於 vector operation R300 有一組平行的 scalar 和 vector pipe 能讓第一個和第二個可以同時執行 |
||||||||
 2003-05-12, 05:40 PM
#51
2003-05-12, 05:40 PM
#51
|

|
|
Major Member
加入日期: Apr 2003
文章: 120
|
給等不及的人參考一下, 偷跑的測試結果:
They have compared the FX 5900 ultra 256MB with ATI Radeon 9700 Pro 128MB. CPU: AMD 2700XP+ In 3DMark2001SE Setting: Default Resolution/FX 5900 Ultra/Radeon 9700 Pro 1024/15178/14667 1280/13508/12481 1600/11874/10556 Setting: 4xAA and 8x AF Resolution/FX 5900 Ultra/Radeon 9700 Pro 1024/11714/9692 1280/9682/7316 1600/7643/5592 UT2k3 - HardOCP High Quality - Antalus Setting: No AA, No AF Resolution/FX 5900 Ultra/Radeon 9700 Pro 1024/166.77/162.57 1280/150.6/117.8 1600/115.73/82.75 Setting: 4xAA and 8x Anisotropic Filtering Resolution/FX 5900 Ultra/Radeon 9700 Pro 1024/119.48/89.33 1280/79.41/58.83 1600/47.69/40.16 http://www.nvnews.net/vbulletin/sho...?threadid=11623 |
||
|
2003-05-12, 06:13 PM
#52
|
|
|
Master Member
  加入日期: Dec 2000 您的住址: Cambridge Law School
文章: 1,780
|
引用:
就我所說的在2個月以內,R350+ 即將出現 |
|
|
2003-05-12, 06:31 PM
#53
|
|
|
Master Member
加入日期: Jun 2002
文章: 2,291
|
引用:
請問Samsung大.....R350+是不是就是.13的R350呢? 或者說R350+是不是就是R390/R420呢?  |
|
|
2003-05-12, 06:44 PM
#54
|
|
|
Registered User
加入日期: Jun 2002 您的住址: 耗電量頗高的地方.
文章: 1,959
|
引用:
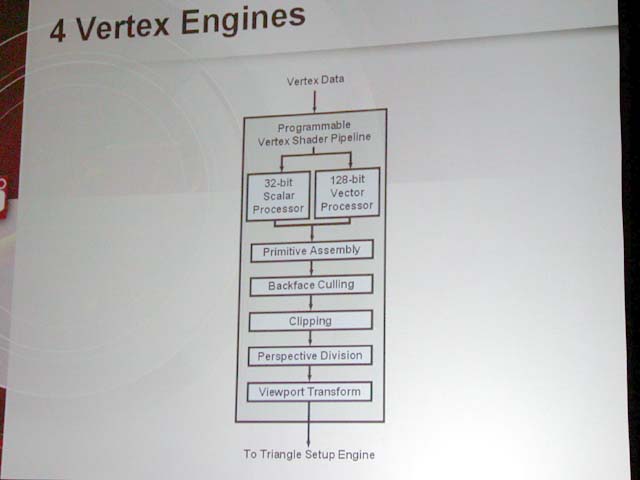 嗯.... 所以是架構問題.... 此文章於 2003-05-12 07:11 PM 被 Artx1 編輯. |
|
|
2003-05-12, 06:55 PM
#55
|
|
|
Master Member
加入日期: Dec 2000 您的住址: Cambridge Law School
文章: 1,780
|
引用:
R350+是0.15製程的R350 |
|
|
2003-05-12, 07:00 PM
#56
|
|
|
Registered User
加入日期: Jun 2002 您的住址: 耗電量頗高的地方.
文章: 1,959
|
引用:
會不會加速到 1280*1024 這個問題, 現在不會以後可能會啊, 別忘了HDTV的解析度是1280x960(D3)和1920*1080(D4), 以後的GPU可能還是得面對這麼大的解析度. 不過那應該會是一段時間以後的事情了, 那時候的技術能不能支持這種設計(16MB eDRAM)就得看看了, 風險能壓到一定程度以下就會採用, 當然至少得等個兩年就是了 (兩年可能還太樂觀), 畢竟一來沒有這種排場要在這麼高的解析度下可能很難快得起來, 相對地快不起來的話也很難有能讓消費者去接受的遊戲品質. 如果能有高速的eDRAM的話, "或許"可以當成off-screen buffer來用, 1k*1k 的 RT Shadow Map 算是一種很可怕的數字了, 畢竟我是在替eDRAM的採用找理由.  我的確認為短期內不會有哪個實作採用eDRAM. 我的確認為短期內不會有哪個實作採用eDRAM.另, 所謂 Z3 是一種FSAA的實作方法, 指在一個 pixel 裡面只存放三個三角面的資料的方法(但可以有十六個 subsamples), 因此,可以在只有三倍負擔的情形下,達到 16X FSAA 的效果; 而且它還可以擴充. 當然,如果一個 pixel 裡面有很多個三角面就會有問題,可是通常這種情形很少見,而且就算偶而出現,也不會有太大的困擾; 事實上 Z3 主要也是從 A-buffer 而來,但是動了一些手腳,以減少所需要的資料量. http://research.compaq.com/wrl/peop...Z3/Z3slides.ppt 此文章於 2003-05-12 07:42 PM 被 Artx1 編輯. |
|
|
2003-05-12, 07:16 PM
#57
|
|
|
Master Member
加入日期: Feb 2002 您的住址: Taipei
文章: 1,611
|
引用:
你看到我的簽名檔案就聯想到某大濕,我是認為他這句話蠻棒的也拿來用... 看來被誤認了.....  = 原來nv30從來沒有辦法"開啟"32Bit FP過,那之前許多硬體網站評論43.03等 幾個比較低分的驅動是因為浮點精度差異的講法就有點違背了.... 個人感覺Nvidia驅動程式似乎還沒有應用一些nv30的特色,以及你所講的強勢指令集等 不知道50.xx以後是否能順利應用這些功能來反應在效能方面 nvidia揮霍一堆電路成本去作那些不知道多久後才會有初步應用的硬體特色於nv30 外加不成熟的GDDRII的搭配(這東西絕對不會比256bit DDR來的好) 怎麼看nv30都像是個實驗產品。 娛樂用顯示卡需要的是"效能至上",太多前瞻性的設計不會增加優勢 反而會成為製程上的阻礙 之前預想nv30實作GDDRII要為了往後產品鋪路,因為DDRII有些DDR未有的電氣方面優點 結果nv40以後才有可能再度實作..... 這還是印證了〝nVidia的產品隔代買就對了〞的講法 Geforce2、Geforce4、FX5900都是完善的產品。 == 順帶一提,專業繪圖評測上,nv30系列(不是說Quadro)成績都還不錯 |
|
|
2003-05-12, 07:45 PM
#58
|
|
|
Master Member
加入日期: Jan 2000 您的住址: 台灣桃園
文章: 1,717
|
引用:
我在po完上一篇文章之後有找到有關Antialiasing的論文有講到Z3,大概稍微 看了一下還沒很用心看所以還一知半解.只知道好處還不少,透明物件可以不 干擾但記憶體使用又比A-Buffer少.不知道會有硬體實作嗎? 啊!剛剛看到您貼的那個網址,每個使用這個技術的硬體要收美金25塊.....  |
|
|
2003-05-13, 09:52 AM
#59
|
|
|
Master Member
加入日期: Jan 2000 您的住址: 台灣桃園
文章: 1,717
|
引用:
這個說法我十分贊同......NV的東西隔代買就沒錯. 我就是這樣做的. |
|
|
2003-05-13, 09:57 AM
#60
|
|





