PCDVD數位科技討論區
(https://www.pcdvd.com.tw/index.php)
- 顯示卡討論區
(https://www.pcdvd.com.tw/forumdisplay.php?f=8)
- - AMD Cinema 2.0 Event (RV770 新世代 GPU 發表) 轉譯自 pc.watch
(https://www.pcdvd.com.tw/showthread.php?t=800029)
|
|---|
AMD Cinema 2.0 Event (RV770 新世代 GPU 發表) 轉譯自 pc.watch
本文 轉譯 及 簡化 於
http://pc.watch.impress.co.jp/docs/2008/0617/amd.htm 及 http://pc.watch.impress.co.jp/docs/...7/kaigai447.htm 在6/16 (Nvidia GT 200 發表日)於美國舉行Cinema 2.0 記者會,會中透露新世代俱備1TFLOPS 處理能力的 ATI Radeon HD 4850 即將在六月二十五日上市。並展示與其競爭對手 GT200 消費電力,價格,與功能特色的比較。 @1TFLOPS處理能力的 Radeon HD 4800 即將於下周上市 低價200美金 且 俱備強大運算性能(1TFLOPS)的 HD4850,在平易近人的價格,仍有相當不錯的繪圖能力。 會中並展示新的相當於電影特效 Ruby Demo    @跳脫傳統思維的GPU設計理念  傳統市場 定位於 250W / 500美金以上的巨大獨立晶片有著電源以及價格成本上的缺點,而且研發期長達6到12個月,相當不利新科技的導入。 而世代產品線,也是從最高階,逐漸刪減功能下來。 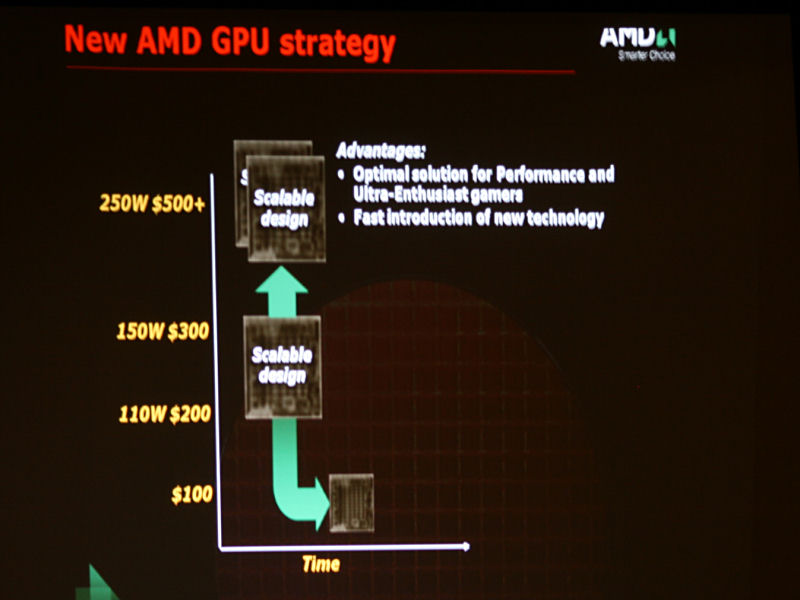 而AMD 新的定位理念,則是將單一晶片的最高階 設定於150W/300美金的區間,往上可多晶片串接,向下則是傳統的單晶片功能刪減的產品 @新世代 GPU 產品線規畫,上市日期  開發代號 上市名稱 對象市場 競爭對手 上市日期 R700 未定 超高階玩家 GT200/9800GX2 八星期內 RV770 XT ATI Radeon HD 4870 高階玩家 9800GTX 7月8日 RV770 PRO ATI Radeon HD 4850 主流市場 8800GT/8800GTS/9600GT 6月25日 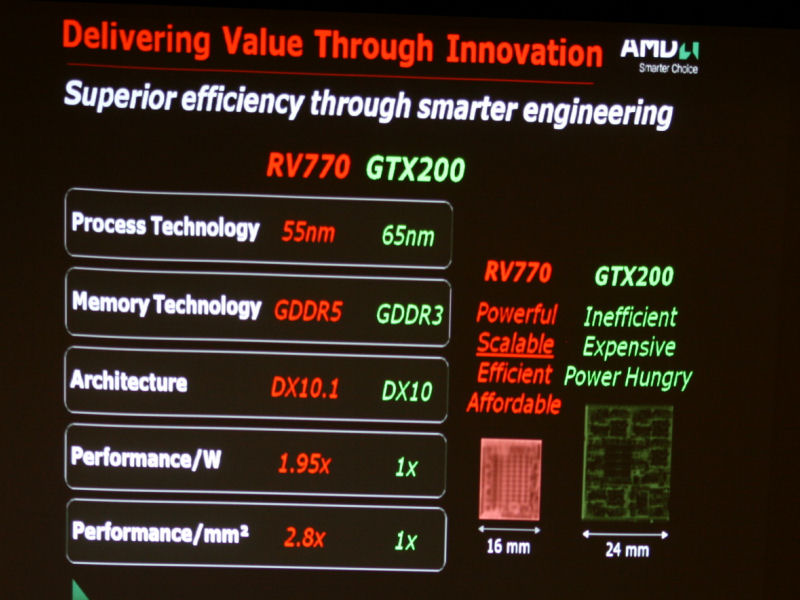 優良的製程,架構,每瓦效率,及面積效率。 |
這....算是跳脫傳統思維嗎? :ase
我沒有看原文啦~~因為也看不懂, 但是我第一個想到Voodoo4的案例。 Voodoo4是單晶片,加上去就變Voodoo5... 這都不重要,重要的是....驅動程式的成熟度跟支援性啊~~ :D 產品性能強好,驅動程式哩哩啦啦,或是遊戲或軟體不支援, 我一直想起SLI跟CF..... :stupefy: |
後藤弘茂 - 評論
@AMD - 1TFLOPS RV770 特點 RV770優點:55nm TSMC 製程,16mm長 面積約250平方mm,9億五千萬電晶體,消費電力約110W 相對同為1TFLOPS的GT200,65nm製程,580平方mm,14億數量電晶體消費電力 峰值200W以上 R700 為兩顆 RV770 組成,並談到GPU定位策略的改變 具有製造容易(良率成本),效能中上,及價格效能比的RV770, http://pc.watch.impress.co.jp/docs/...7/kaigai04l.gif 接下來談到 NVIDIA Instruction-Level Parallelism指令階層的平行化, 與AMD VLIW(Very Long Instruction Word),理論效能的實現與效率 接著 GPU的泛式運算 談到AMD BrookGPU 與NVIDIA CUDA 對於異質運算的幫助 @GPU 設計路線的分野 談到 NVIDIA 470 平方 mm的GeForce 8800(G80) 與570 平方mm 的GeForce GTX 280(GT200),巨大化的體積,以及相當耗電 巨大化帶來的耗電,與製造良率問題。 相對的頻率降低與電力密度的上升 http://pc.watch.impress.co.jp/docs/...17/kaigai07.gif @AMD的從前與未來 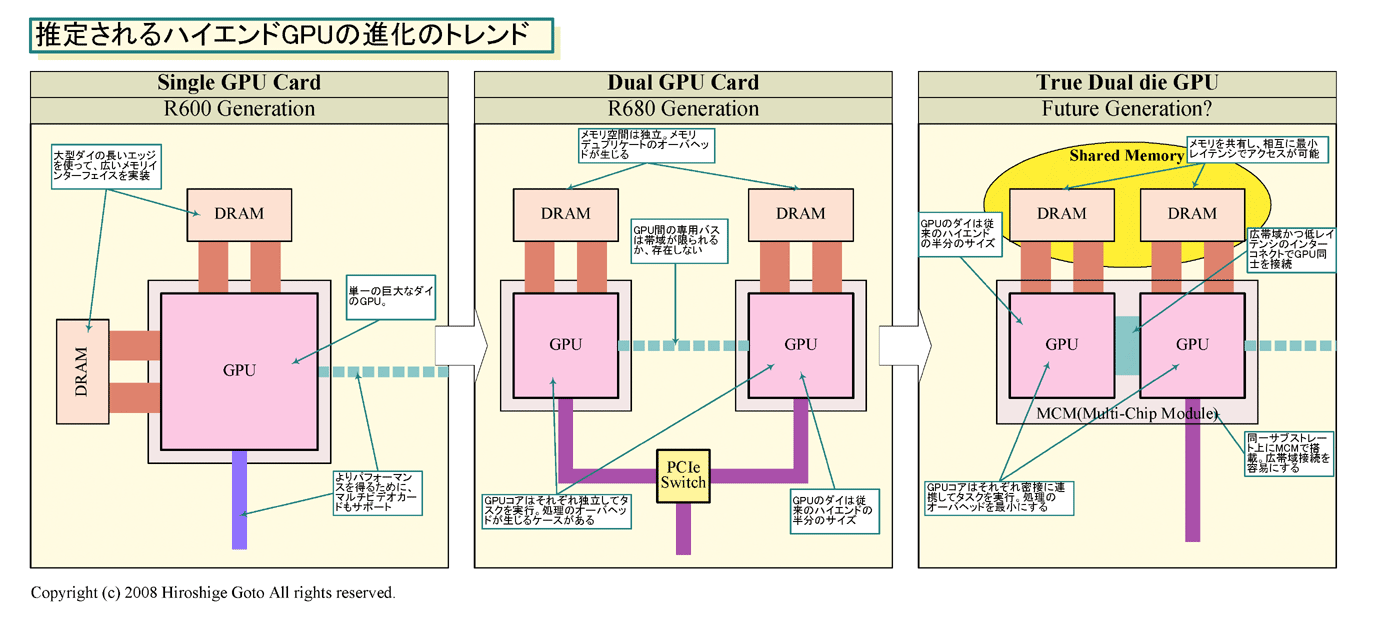 巨大化的R600-->PCIe Swtich串接的R600與獨立的記憶體-->封裝整合的雙晶片(像XBOX 360 Xenos 的 ROP EDram與主晶片的封裝整合,有頻寬與連接速度的優勢) |
個人感想--
NVIDIA 的Instruction-Level Parallelism 似乎走到了死胡同 Instruction-Level Parallelism 效能似乎對於電晶體數量,與記憶體頻寬設計,相當關連。 ILP 為了提升效能,有提升SP效率,增加SP數量,Thread dispatch的效率改善,ROP的搭配等方法。 再來便是記憶體頻寬與SP數量的搭配,增加SP數量,相對的記憶體頻寬需求也是正比的增加。 在製程限制(過大晶片),與記憶體限制(PCB 走線,寬度不可能無限上增)。 對於未來NVIDIA高階產品線,我是抱持著疑慮的態度。 另外一方面 AMD VLIW 架構也到了收成的時候 驅動也逐漸能發揮VLIW的效能,再者記憶體頻寬也不太吃。多塞SP。也不會像NVIDIA一樣吃電晶體。似乎有倒吃甘蔗之勢.... 可能的未來 NVIDIA 可能會逐漸走向ILP跟VLIW的混合架構。 另外 GPU泛式運算,可能會有統合的API,(Apple grand central,OpenCL) |
引用:
冒著等一下可能會被NV fanboy譙的可能+1 單晶片越做越大已經是不可避免的事 再大下去甚麼良率成本都不管,光是對user來說就會很困擾 ATi 的雙核如果可以不透過PCIe Switch那效率應該會好很多吧 感覺這部分ATi是領先NV的 不過ATi在VLIW的效能我個人是持保留態度,畢竟這不是件簡單的事 至少目前還沒看到RV770對於SP利用率有明顯比R600/RV670好很多的證據 此外,NV拉攏遊戲開發者的能力與投注資源,短時間內ATi是難以撼動的 所以ATi 還是得加油才行 |
目前來看就是這樣, 現行架構下要提高效能, 就要多塞幾個管線進去, 無可避免一定會越做越大
除非再來個架構番新, 提升單個 SP 的效率, 不然這個趨勢一定會持續下去, 雖然個人偏好單晶片架構, 但是耗電問題是真的很頭痛, 短期內是可以靠 Hybrid SLI 解決, 但是長期來說還是要有解決的方案, 個人認為, 耗電部分NV 可以開發成允許關閉部分核心, 像 2D 顯示的時候只需要開啟少部分的 SP 來做桌面的渲染, 如此應該會比Hybrid SLI 要透過內建顯示來的有效且簡單 至於AMD,將來應該會利用他的環形記憶體架構, 把兩個核心串起來, 共享記憶體資源以減低雙晶片造成的延遲 |
引用:
我認為製程可以解決這個問題 但是台積電的研發速度似乎跟不太上 顯示卡的發展速度... |
引用:
NVIDIA是說要 六個月到九個月 效能要一翻 摩爾定律 是18個月 電晶體數量 會一翻 ILP效能要一翻,電晶體差不多也一翻 NVIDIA最後會被製程搞得很囧 XD |
不過demo 好像比nV的還好看
|
製程問題的話NV不找台積電代工,去找Intel代工可能又會翻盤一次
反正哪邊便宜又好就往哪邊倒就對了 NV-PS3 ATI-XBOX360 目前來看360價格/畫面/遊戲/連網都站了上風 |
| 所有的時間均為GMT +8。 現在的時間是10:29 AM. |
vBulletin Version 3.0.1
powered_by_vbulletin 2025。